About Data(1)
1. Data Set의 유형
- Record : Database에서 가장 많이 다루는 유형
- Relational records(관계형 레코드) : Table의 형태로 Relational Database에서 사용
- Attribute(Column, field, variable, dimension, feature) : Data Entity의 특성을 설명
- Tuple(Row, Record, instance, Data object, Sample) : 하나의 Data Entity를 설명

- Document Data : Text Document를 term-frequency의 vector 형식으로 표현
-> Document 간의 유사성 파악 가능
- ex) Document1 = 5, 0, 3, 0, 2, 0, 0, 2, 0, 0
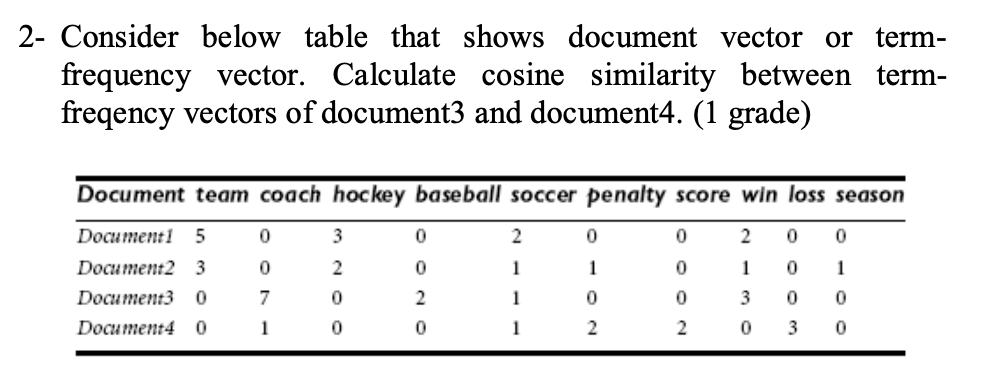
- Transaction data : 거래를 저장하는 Database에서 사용

- Graph and Network - ex) World Wide Web, Social or Informational Networks
- Ordered : 특정 순서로 정리된 Data
- Video Data : 여러 Image의 Sequence로 구성
- Temporal Data : 시간에 따라 변화하는 Data ex) 날씨, 온도....
- Sequencial Data, Genetic Sequence Data
- Spatial, Image and Multimedia - ex) Map, Image, Video...
2. Data Objects
: 하나의 Entity를 표현하는 Data
- other name : sample, example, instance, data point, object, tuple
- 예시:
- sales database : 손님, 가게 물품, 판매......
- medical database : 환자, 치료.......
- university database : 학생, 교수, 강의.......
- Data set은 여러 Data Object로 구성
- Data Object는 여러 Attribute로 설명됨
- Database Table의 row = Data Object
- Database Table의 column = Attrbute
3. Attribute
: 한 Data Object의 특성, 성격을 나타내는 Field.
- other name : dimension, feature, variable
3-1. Attribute의 타입
1. Nominal (명목형) : 어떤 범주의 항목이나 상태, 이름에 해당하는 Data
- other name : Category(범주형)
- ex) Hair_Color = {black, blond, brown, grey, red, white}
marital status, occupation, ID numbers, zip codes.....
2. Binary (이진형) : 두 가지 상태(0 / 1)만을 지니는 Nominal type Attribute
- Symmetric binary : 두 결과의 중요성의 같음 ex) On/Off, Marital Status
- Asymmetric binary : 두 결과의 중요성이 다름, 일반적으로 더 중요한 결과에 1을 부여
ex) medical test - positive/negative(양성/음성)
3. Ordinal (순서형) : 각각의 값이 유의미한 순서를 따르는 경우의 Data
- ex) SIze = {Small, Medium, Large}, grades, army rankings
4. Numeric (숫자형) : 값이 수치나 Qualtity로 나타나는 Data(실수형, 정수형)
- Interval (구간형) : 값들 간의 순서가 있으며, 같은 간격의 구간으로 나누어져 측정되는 Data
- 절대적 원점(zero point)의 의미가 없다.
- ex) ℃ (섭씨), ℉ (화씨)로 나타나는 온도, 날짜, 시간....
- Ratio (비율형) : 값들 간의 순서가 있으며, 각 값들은 기본 단위의 배수로서 다뤄질 수 있음
- 절대적 원점이 존재함
- ex) ºK (절대 온도)로 나타나는 온도, 길이, 개수, 금액.....
4. Data의 통계적 묘사
- Data는 수치, raw material이므로 이를 더 잘 이해하기 위해서 통계적인 방법으로 데이터를 나타냄
ex) Central Tendency(중심경향성, 집중경향성), Variation(분산도, 산포도).....
- Data의 특성을 중앙값(median), 최솟값/최댓값(max/min), 분위수(quantile), 극단치(outlier), 분산(variance)...등으로 표시
- 분산 분석(Dispersion Analysis) - Boxplot. Quantile Analysis
4-1. 중심 경향치 측정
1. Mean(산술 평균)

- 가중 평균(Weighted Mean) : 각 값에 중요도에 해당하는 가중치를 곱하여 계산한 평균값

- 절사 평균 (Trimmed Mean) : 극단값들을 배제하고 계산한 평균값
2. Median(중간값, 중앙값) : 값을 순서대로 정렬했을때, 전체의 중앙에 위치하는 값
- 전체 값의 수가 홀수라면 중간의 값 하나로, 전체 개수가 짝수라면 중간의 두 값의 평균으로 나타남

3. Mode (최빈값) : 가장 자주 나타나는 Data
- 최빈값의 개수에 따라 unimodal, bimodal, trimodal...
- 경험에 따른 공식이 존재
: Mean - Mode = 3 x (Mean - Median)
4. Symmetric vs. Skewed Data
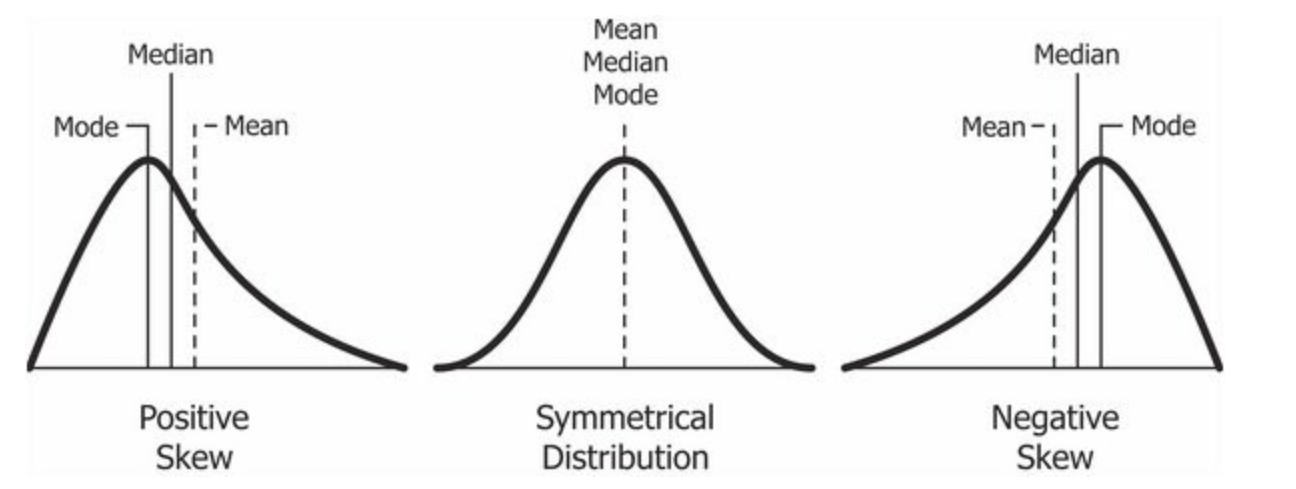
- Symmetric Data : Mode = Median = Mean
- Positively Skewed : Mode < Median < Mean
- Negatively Skewed : Mode > Median > Mean
5. Data의 분산 측정
1. Quantile (분위수) : 데이터를 크기로 정렬했을 때, Q1 = 25번째 값, Q3 = 75번째 값
- Q0 = 최솟값(Min), Q2 = 중앙값(Median), Q4 = 최댓값(Max)
- IQR(Inter-Quartile Range, 사분 범위) = Q3 - Q1
- Five number Summary : Q0(Min), Q1, Q2(Median), Q3, Q4(Max)의 다섯개 값으로 분포를 파악
2. Box plot (상자 도표) : five number summary를 이용해 Data를 박스의 형태로 표시
- 박스의 양 끝은 Q1과 Q3에 존재 -> 박스의 길이 = IQR
- 중앙값(Median)은 박스 내에 굵은 선으로 표시
- 박스에서 최솟값과 최댓값까지를 점선으로 연결하여 표시
- Outlier : (Q1 - 1.5 x IQR)보다 작거나, (Q3 + 1.5 x IQR)보다 큰 값, 최솟값, 최댓값에서 제외하고, 범위 외의 점으로 표시

3. Variance (분산)과 Standard Deviation(표준 편차)
- 분산

- 표준 편차 : 분산의 제곱근
* 정규 분포의 특징

- μ - σ 에서 μ + σ 까지의 구간 = 전체의 약 68%
- μ - 2σ 에서 μ + 2σ 까지의 구간 = 전체의 약 95%
- μ - 3σ 에서 μ + 3σ 까지의 구간 = 전체의 약 99.7%
6. 통계 분석의 시각적 표현
1. Box plot : five number summary를 이용해 데이터를 박스로 표현
2. Histogram : 도수분포표를 막대 형태로 하여 시각화 한 것
3. Quantile plot : Quantile (분위수)에 대한 정보를 시각화
- data를 오름차순으로 정렬하고, data 값과 해당 데이터의 백분위를 점으로 표시

4. Quantile-Quantile plot (Q-Q plot) : 두 Quantile 분포를 비교하여 시각화
- 비교를 돕기 위해 값의 Quantile이 같은 선, 즉 기울기가 1인 선을 그려 넣음

5. Scatter plot (산점도) : 변수가 2개인 데이터의 그래프상 위치를 점으로 표시

- 두 변수에 관계에 따라 positively correlated, negatively correlated, uncorrelated data로 구분
